10/31/2010: For our annual Halloween post we take a strong pro-robot position. We are serious.
The UO President’s and Provost’s websites have recently added computer code that hides their content from Google and prevents public access to the archives maintained by the Internet Archive.
Indexing and archiving services use robots – simple computer programs – to crawl websites and index and archive them. The robots report back on the sites and their links, making them easily available to the public via web searches. No robots, no Google. And all is lost.
Sometimes websites use a robots.txt file. This file generally contains instructions telling robots how long to wait between requests so servers aren’t overloaded, and so on. In the past UO websites have followed generally accepted practices for robot control. See for example the Office of Institutional Equity and Diversity file. Reasonably robot friendly.
However, the file at http://president.uoregon.edu/robots.txt was recently changed to read
User-agent: *
Disallow: /
as was the Provost’s robots.txt file. This was done by a human. The * means attention all robots. The / means go away and don’t index any content in the website except the basic homepage. Tricky. Use of a blanket disallow of this sort is extremely unusual, especially for a public agency. Most sites don’t even have a robot.txt file.
This intentional anti-transparency move prevents Google and so on from indexing President Lariviere’s and Provost Bean’s UO websites. Try this search command. You will get only a few hits, and none of the typical Google archive links. Additionally, President Lariviere’s site has disappeared from the Internet archive:
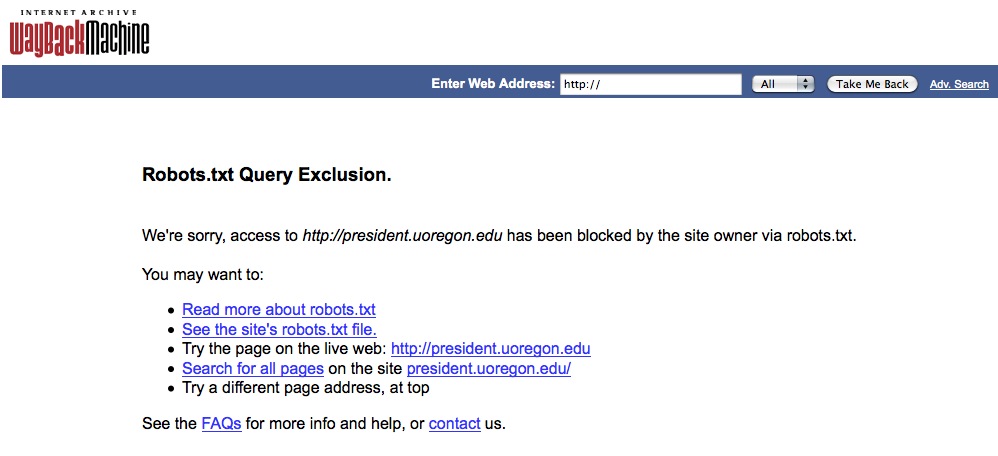
This decision to block robots prevents access to years of archives, going back to the beginning of Frohnmayer’s administration. When was this done? Well, to know that we’d have to check the Internet Archive …. Nice work, Winston.
It is trivial to write a script which will ignore the robots.txt file and mirror president.uoregon.edu – except for the robots.txt file – to another domain, which Google and the Internet Archive will then accept. The bash command wget -U option was designed just for this. The people who made the web do not like censorship. But why play this stupid game – let’s just go back to letting the public see public records, OK? Delete the / and free the robots!
10/31/2010, 9:07 PM update: The robot wars are over. The websites for the President and the Provost now have new robots.txt files:
User-agent: *
Disallow:
The googlebots are hitting them right now. They will soon be searchable with Google, and archived again on the wayback machine at internetarchive.org Thanks to the anonymous UO administrator who checks this blog on Halloween and who knows how to get shit done. Now, what about those resumes for Randy Geller and Liz Denecke?